This article is the fifth and last of a serie of five about how to code a one-pixel sine scroll on Amiga, an effect commonly used by coders of demos and other cracktros. For example, in this cracktro by Angels:

In the first article, we learned how to install a development environment on an Amiga emulated with WinUAE, and how to code a basic Copper list to display something on the screen. In the second article, we learned how to set up a 16×16 font to display the columns of pixels of its characters, and to use triple buffering to display the pictures on the screen without any flickering. In the third article, we learned how to draw and animate the sine scroll, first with the CPU then with the Blitter. In the fourth article learned how to add some bells and whistles to the sine scroll with the help of the Copper, namely a shadow and a mirror.
In this fifth and last article, we shall optimize the code so that the main loop runs at the frame rate of 1/50th of second. We shall also protect the code against the assaults of lamers trying to hack the text. Finally, we shall wonder what may be learned today from such a coding session on the Amiga.
Click here to download the archive of the source and data of the program hereby explained.
If you’re using Notepad++, click here to download and enhanced version of the UDL 68K Assembly (v3).
NB : This article may be best read while listening to the great module composed by Nuke / Anarchy for the diskmag part of Stolen Data #7, but this is just a matter of personal taste…
Cliquez ici pour lire cet article en français.
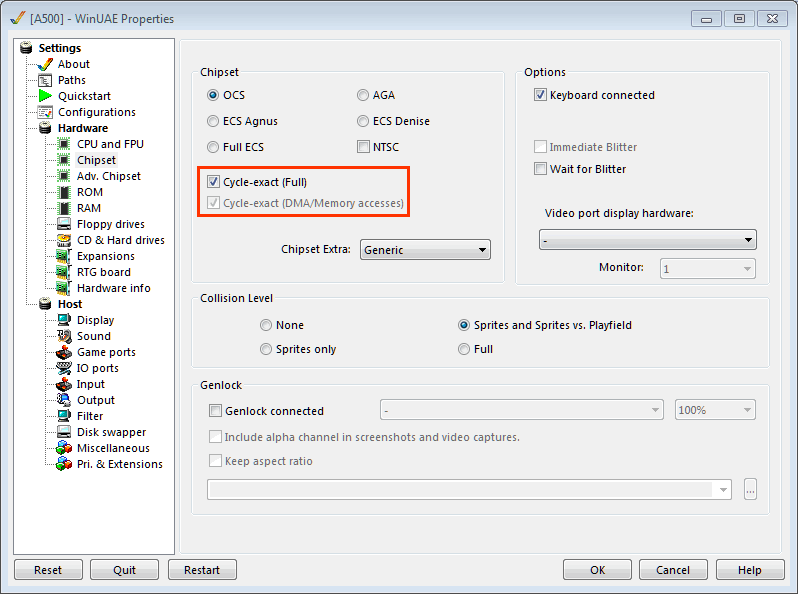
10/27/2018 update: A new section has been added after I discovered that the “Cycle-exact” option had not been activated in WinUAE.
Precompute to run at the frame rate
Our sine scroll is a one-pixel one, which is better than the one created by Falon shown in the first article, but it runs on Amiga 1200 and not Amiga 500, the Amiga 1200 being a much faster computer! To know if our code is efficient, we have to run it on Amiga 500.
For this purpose, we shall copy the executable on a disk, and have have an emulated Amiga 500 boot with this disk.
In ASM-One, we use the commands A (Assemble) to assemble, then WO (Write Object) to create an executable and write it in SOURCES: with the name sinescroll.exe. Next, we switch to the Workbench. We double-click on the icon of the drive DH0, then the icon of the System folder, and last on the icon of the Shell.
Let’s press F12 to switch to the configuration of WinUAE. In the Hardware section, we click on Floppy drives. Then we click on Create Standard Disk to create a formated disk as an ADF file. We click on … to the right of the DF0: drive, and we select this file to emulate the insertion of this disk in this floppy drive. Finally, we click on OK to switch to the Workbench.
In the Shell, we execute this sequence of commands that shall execute sinescroll.exe if we boot from the disk:
install df0: copy sources:sinescroll.exe df0: makedir df0:s echo "sinescroll.exe" > df0:s/Startup-Sequence
The archive mentioned in the begining of this article contains the ADF file of the disk.
Next, we create an emulated Amiga 500 – we shall need the Kickstart 1.3. Once it is done, we insert the disk in DF0: and start the emulation by clicking on Reset. The sine scroll runs immediately.
This almost runs at the frame rate – let’s be honest, it doesn’t run fast enough at all. It would be difficult to create a sine scroll as beautiful as Falon did… Well, we could use a trick. It won’t be documented here, but the idea would be to double the lines at almost no expense by telling the Copper to update the modulos at each line in order to repeat each line once. The result would not be as accurate, but it could fool people.
This would not make our code more efficient, though. Hopefully, since we wrote it without regards for its performance, it shall not be very difficult to find ways to save a bunch of CPU time cycles.
First, we should have a look at the M68000 8-/16-/32-Bit Microprocessors User’s Manual, that details the time cycles the execution of each and every variant of the CPU instructions requires. We should also refer to the Amiga Hardware Reference Manual, that explains how the CPU and the various coprocessors that benefits from a DMA share the video cycles during the drawing of a line – the pretty figure 6-9 of the manual.
Next, we should work on the algorithm to come up with an efficient code regarding the number of such cycles it consumes. As always, the first instinct should always be to find a way to remove from the main loop everything that may be precomputed, since memory to store the results of precomputations is available.
For example, the ordinate of each column may be precomputed for each value of the angle between 0 and 359 degrees. This way, the code in the main loop would not be this one anymore…:
lea sinus,a6 move.w (a6,d0.w),d1 muls #(SCROLL_AMPLITUDE>>1),d1 swap d1 rol.l #2,d1 add.w #SCROLL_Y+(SCROLL_AMPLITUDE>>1),d1 move.w d1,d2 lsl.w #5,d1 lsl.w #3,d2 add.w d2,d1 add.w d6,d1 lea (a2,d1.w),a4
…but this one:
move.w (a2,d0.w),d4 add.w d2,d4 lea (a0,d4.w),a4
It would also be possible to analyze the text before the main loop to create a list of columns for this text. This way, some twenty lines, that are executed on in the main loop, may be removed and replaced with these few ones:
cmp.l a1,a3 bne _nextColumnNoLoop movea.l textColumns,a1 _nextColumnNoLoop:
Once we are done with precomputing, we may refactor the code that remains in the main loop. For example , we may simplify the loop that waits for the Blitter…:
_waitBlitter0\@ btst #14,DMACONR(a5) bne _waitBlitter0\@ _waitBlitter1\@ btst #14,DMACONR(a5) bne _waitBlitter1\@
…like this:
_waitBlitter0\@ btst #14,DMACONR(a5) bne _waitBlitter0\@
Or we may store beforehand $0B4A in the data register of the CPU (here, it is D3) that is used to store a value in BLTCON0 when some column is drawn with the Blitter… :
move.w d3,d7 ror.w #4,d7 or.w #$0B4A,d7 move.w d2,BLTCON0(a5)
…which gives (to move to the next pixel, add $1000 to D3 instead of 1, and test the flag C of the CPU internal conditions register with BCC to detect an overflow at the 16th pixel; the overflow resets D3 with the expected value $0B4A, which means that we don’t have reset D3 ourselves!) :
move.w d3,BLTCON0(a5)
The source of this optimized version is sinescroll_final.s, which may be found in the archive mentioned at the beginning of this article.
As a bonus, this source contains some code that computes the number of lines that the electron beam displays between the beginning and the end of one iteration of the main loop. This code shows the number of lines in a decimal format in the top left corner of the screen – in PAL, the maximum number of lines is 313. The color 0 is set to red at the beginning of the loop, and to green at the end of it.
This way, we can see that the main loop takes 138 lines to display the sine scroll on Amiga 500 (left), and 54 lines only on Amiga 1200 (right):

|

|
This saves a lot of CPU time cycles, but not that much on Amiga 1200 where the number of lines decreases from 62 to 54, which is 13% less – for information, the number of lines of the version that draws the lines with the CPU instead of the Blitter decreases from 183 to 127, which is 31% less!
Any CPU time cycle is good to save, but we shall remind that precomputing requires memory. Precomputing also creates some lag, since the user has to wait for the precomputing to be complete if its results have not already been stored as data linked with the code in the executable. In this case, precomputing the columns for the whole text requires 32 byter per character, which means 34 656 bytes for the 1 083 characters in the text. Well, that’s not that much.
So, the sine scroll was not running at the frame rate of 1/50th of a second on Amiga 500. After its code has been optimized, we have plenty of time to add some new bells and whistles! Let’s do it. We shall add a rotating vectorial star in the background, casting a shadow and reflected in the mirror as does the sine scroll – those last effects don’t cost any more CPU time cycle. How the vectorial star works is not detailed here, but the code may be found in sinescroll_star.s in the archive mentioned at the beginning of this article:

The main loop now takes 219 lines on Amiga 500 and 103 lines on Amiga 1200, without any optimization – in paticular, the whole bitplane that contains the star is filled with the Blitter, although it is useless to fill the horizontal strips before and after the star in this bitplane. We could easily stretch the sine scroll vertically by playing on the modulos with the Copper, add a starfield made of sprites that the Copper would repeat, add a beautiful module composed by Monty, and so on. But that’s another story…