This is the second of a serie of five articles about how to code a one-pixel sine scroll on the Amiga, an effect commonly used by coders of demos and other cracktros on this machine… until it was outmoded when Red Sector Inc. (RSI) made it possible for any lamer to create its own with the famous DemoMaker:
In the first article, we learned how to install a development environment on an Amiga emulated with WinUAE, and how to code a basic Copper list to display something on the screen.
In this second article, we shall transform a 16×16 font to easily display its columns of pixels, precompute the values of the sine table required to deform the text by modifying the ordinates of those columns, and set up a triple buffering to avoid flickering when switching the picture that is displayed.
Click here to download the archive of the source and data of the program hereby explained.
If you’re using Notepad++, click here to download and enhanced version of the UDL 68K Assembly (v3).
NB : This article may be best read while listening to the great module composed by Nuke / Anarchy for the diskmag part of Stolen Data #7, but this is just a matter of personal taste…
Cliquez ici pour lire cet article en français.
Create a 16×16 font of properly arranged pixels
Half a loaf is better than none. Since no 16×16 font file may be found in my archives, we shall use a 8×8 font and double the length of its sides. The result won’t honor the one-pixel precision of the sine scroll but this way, we may proceed.
The font8.raw file contains the 8×8 font. Note that the INCBIN directive is the way to tell ASM-One to link the assembled code with the data read from the file:
font8: INCBIN "sources:2017/sinescroll/font8.fnt"
The font is a serie of 94 ASCII characters in the ascending order of their ASCII codes. Each character comes as a 8×8 bits matrix which bytes are given in the order of the lines of pixels the character is made of, from the top one to the bottom one – this is the bitplane of the character. In more graphic terms, the font looks like this – the way the data are arranged in the memory is different:
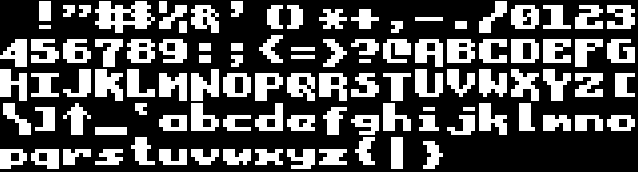
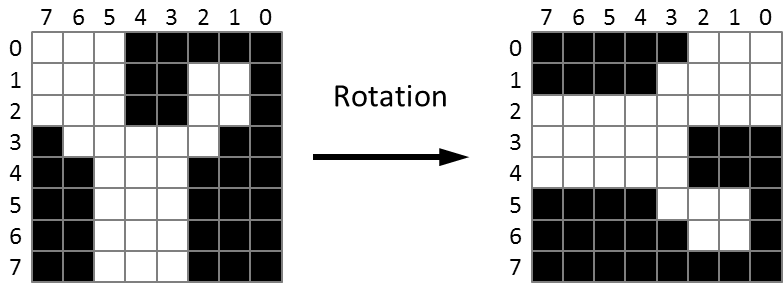
We have to draw the columns of pixels of a character at various heights to create the sine scroll. When drawing the column N, we certainly don’t want not loose precious CPU time cycles by reading line 0, extracting the value of bit N, then setting or clearing the matching pixel in the screen, and repeating the whole process with the remaining 7 lines. What we want to do is to read all 8 values of bit N and draw the column N in a row. This means that we have to apply a -90 degrees rotation to the bitmap:
Since we want to use a 16×16 font, let’s make the most of the opportunity by also doubling each line and each column:

Rotation and scaling are achieved with the following code, that is quite simple:
lea font8,a0 move.l font16,a1 move.w #256-1,d0 _fontLoop: moveq #7,d1 _fontLineLoop: clr.w d5 clr.w d3 clr.w d4 _fontColumnLoop: move.b (a0,d5.w),d2 btst d1,d2 beq _fontPixelEmpty bset d4,d3 addq.b #1,d4 bset d4,d3 addq.b #1,d4 bra _fontNextPixel _fontPixelEmpty: addq.b #2,d4 _fontNextPixel: addq.b #1,d5 btst #4,d4 beq _fontColumnLoop move.w d3,(a1)+ move.w d3,(a1)+ dbf d1,_fontLineLoop lea 8(a0),a0 dbf d0,_fontLoop
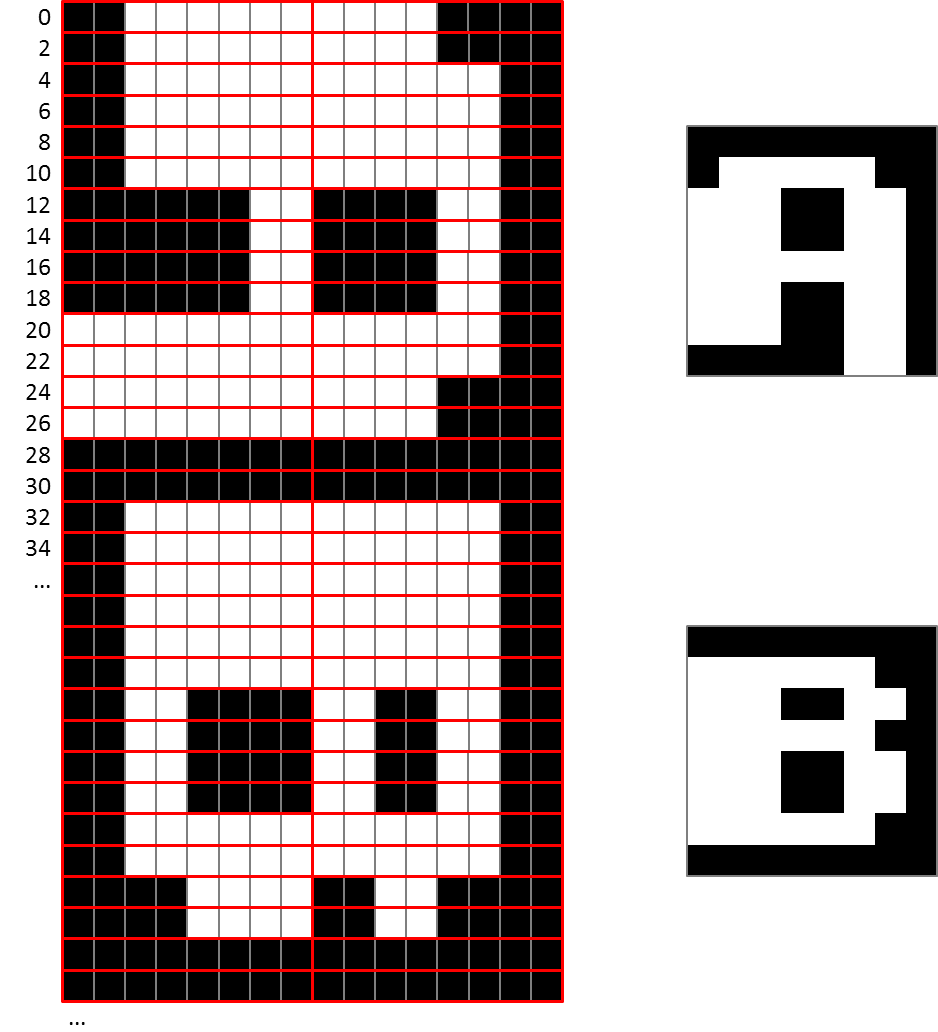
In this code, the new 16×16 font is stored at the address contained in font16. This is a memory space of 256*16*2 bytes that we allocated previously: 256 characters of 16 lines of 16 pixels (2 bytes) each, which contents looks like a set of flipped characters:
Scroll the text at the frame rate of 1/50 of a second
After the initialization comes the main loop. Its structure is very simple:
- wait for the electron beam to reach the bottom of the display window; easy
- draw the text starting from a given column of a given character in the text (a position) and increment / loop this position;
- check if the user clicks the left mouse button, and end the loop if he does / keep looping if he doesn’t.
To wait for the electron beam, we just have to read its vertical position coded on 9 bits: bit 8 lies in VPOSR and the remaining bits 0 to 7 lie in VHPOSR. It is very important not to read bits 0 to 7 only, because since the display is PAL, we may wish to wait for the electron beam at some height DISPLAY_Y+DISPLAY_DY that would be greater than $FF. Indeed, this is the case since $2C+256 gives 300…
It would be possible to wait for the hardware to tell us that it has fully drawn the frame. To do so, we would loop until the VERTB bit has been set in INTREQ and then clear this bit – the hardware never clears by itself a bit it has set in INTREQ:
_loop: move.w INTREQR(a5),d0 btst #5,d0 bne _loop move.w #$0020,INTREQ(a5)
This would work, but it would not happen until line 312 has been drawn – the last of the 313 lines in PAL -, and line 312 is far beyond from DISPLAY_Y+DISPLAY_DY, the line after which we have nothing more to draw. So we better wait for the electron beam to reach this latter line instead of line 312, and start to render the next frame immediately. This saves some precious time.
The code presumes that the amount of time required for one main loop is greater than the amount of time the electron beam requires to draw the lines DISPLAY_Y+DISPLAY_DY to 312. Should this not be the case, we should add a test to wait for the electron beam at line 0. This should slow the main loop and keep it synchronized with the electron beam, which means that the main loop should run in 1/50th of a second in PAL.
To test if the user presses the left mouse button, we just have to test bit 6 of CIAAPRA. This one of the 8 bit registers of one of the 8520 that control the inputs and outputs. Its address is $BFE001.
_loop: _waitVBL: move.l VPOSR(a5),d0 lsr.l #8,d0 and.w #$01FF,d0 cmp.w #DISPLAY_Y+DISPLAY_DY,d0 blt _waitVBL ;Code to execute here btst #6,$bfe001 bne _loop
More serious things shall now be considered. The first task that must be completed at the begining of the frame is to display the bitplane where the sine scoll has been drawn during the previous frame. This is how the double buffering runs: if you want to avoid flickering, never draw in the bitplane that is being displayed.
|
Flickering and double buffering
Consider this. We have to draw a red “R” on a green background by overwriting a blue “Y” on a yellow background. As we start drawing in the bitplanes, the electron beam is reading them to draw the picture on the screen. It is possible that we start drawing the “R” after the electron beam has already displayed a good part of the “Y”. Since the CPU takes much less time to write in the bitplanes than the electron beam takes to read and display them, the CPU may overwrite some part of the bitplanes that has not already been displayed by the electron beam. The result is that the electron beam read some data after rather than before the CPU has overwritten them, and thereby displays some part of the “R” after some part of the “Y”:
If the picture changes with each frame, this race between the electron beam and the CPU creates an overlapping of successive pictures at a position that may vary: this is what flickering means.
To avoid this, we have to write the “R” in hidden bitplanes, which means bitplanes that are different from those where the “Y” is drawn, those latter bitplanes being displayed. When the frame ends, we have to display the bitplanes where the “R” has been drawn, and start drawing the next character in the bitplanes where the “Y” has been drawn, once those latter bitplanes are off-screen. This is called double buffering.
|
We won’t be using double buffering, though. Since the Blitter has a DMA, it can erase a bitplane while the CPU is drawing in another bitplane, and the hardware is displaying a third one. This is triple buffering:

First, let’s roll the three bitplanes… :
move.l bitplaneA,d0 move.l bitplaneB,d1 move.l bitplaneC,d2 move.l d1,bitplaneA move.l d2,bitplaneB move.l d0,bitplaneC
…then update the address of the bitplane to be displayed in the Copper list (recode the MOVE that stores it in BPL1PTH et BPL1PTL):
movea.l copperlist,a0 move.w d1,9*4+2(a0) move.w d1,10*4+2(a0) swap d1 move.w d1,11*4+2(a0) move.w d1,12*4+2(a0)
Now, we may tell the Blitter to erase the bitplane that was previously displayed:
WAITBLIT move.w #0,BLTDMOD(a5) move.w #$0000,BLTCON1(a5) move.w #$0100,BLTCON0(a5) move.l bitplaneC,BLTDPTH(a5) move.w #(DISPLAY_DX>>4)!(256<<6),BLTSIZE(a5)
As explained in a previous article, the Blitter may logically combine the bits from sources memory blocks into a destination memory block. The combination must be described by setting bits in BLTCON0 for so-called minterms. It is a logical combination with AND or OR of data from sources A, B and C that may be negated with NOT - for example, D=aBc+aBC+ABc+ABC, which gives D=B: the source memory block B must be copied into the destination memory block D as is. If we set D=0 by clearing all the minterms bits in BLTCON0, we tell the Blitter to fill the destination memory block D with 0.
The Blitter runs while the CPU is running. This means that we don't to wait for the Blitter to have fully erased one bitplane before we start drawing in another bitplane with the CPU, while yet another bitplane is being displayed on screen. We shall only wait for the Blitter when times comes for drawing a character by... drawing lines!
Deform the text along a sine curve
A one-pixel scroll means that the 16 columns of pixels of a character are drawn at various ordinates, those ordinates being computed by a sine fonction applied to an angle that is incremented after each column.
This means that the formula for computing the ordinate of column x is:
y=SCROLL_Y+(SCROLL_AMPLITUDE>>1)*(1+sin(βx))
...where βx is the value of angle β for column x, this value being incremented by SINE_SPEED_PIXEL degrees at the next column.
Note that the amplitude for the coordinates is [-SCROLL_AMPLITUDE>>1, SCROLL_AMPLITUDE>>1], which matches a height of SCROLL_AMPLITUDE+1 if SCROLL_AMPLITUDE is even and SCROLL_AMPLITUDE if this value is odd.
For example, if SCROLL_Y=0, SCROLL_AMPLITUDE=17 and SINE_SPEED_PIXEL=10 :
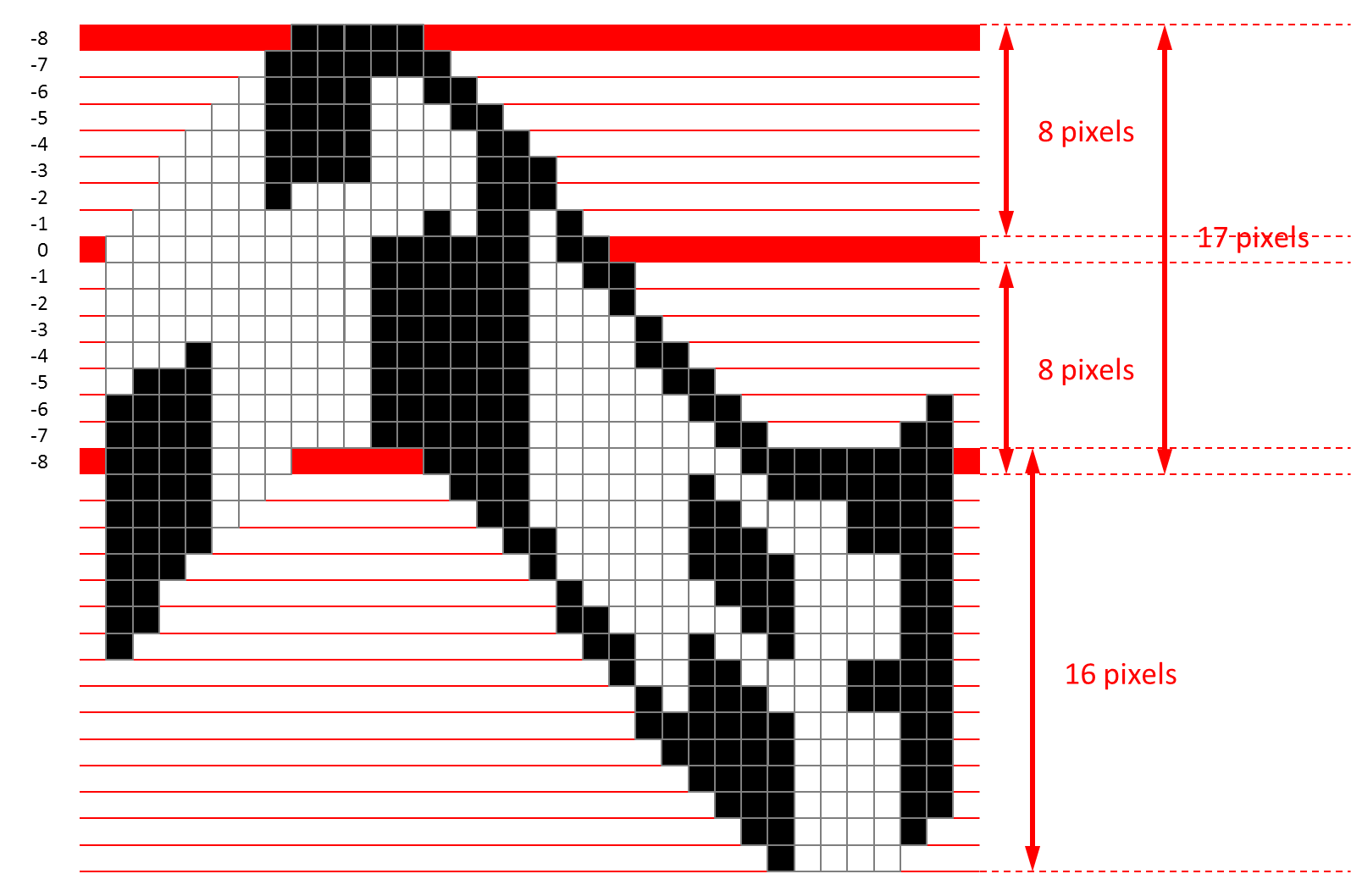
Oops! we missed something: there is no sin() function among the instructions of the MC68000. Since we can't call a function from a library that would require a lot of costly CPU time cycles to compute a sine value, we shall precompute the sine value for each angle between 0 and 359 degrees, by step of 1 degree. In other words, we shall keep the sine values at hand in a ready to use table.
Re-oops! we missed something else: we can't handle floating numbers. For the same reason, we shall precompute the sine values as integers. Since the amplitude of those values is [-1, 1], we shall multiply those values by a factor, or this would boil down to -1, 0 and 1. In Excel, this means that we shall compute ARRONDI(K*SIN(A);0), K being the factor and A being the angle.
This factor is not choosen randomly. A sine value will be used in a multiplication, which means that a division shall follow. Because we want to spare CPU time cycles, we shall not use the instruction DIVS that consumes too much of them. Instead, we shall shift the result of the multiplication by some bits to the right, which means perform an integer division which divider is a power of 2. The factor shall be 2^N.
We choose to set N to 15 for accurate sine values and for the opportunity to use a SWAP instruction (16 bits shift to the right, which is dividing by 2^16) followed by a 1 bit ROL.L instruction (1 bit shift to the left, which is multiplicating by 2). This will consumes far much less CPU cycles than a 15 bits ASR.L instruction. This way, the sine table looks like that:
sinus: DC.W 0 ;sin(0)*2^15 DC.W 572 ;sin(1)*2^15 DC.W 1144 ;sin(2)*2^15 DC.W 1715 ;sin(3)*2^15 ;...
A little problem remains. Mutiplicating by 2^N leads to a 16 bits overflow when the sine value is -1 or 1. For example, 1*32768 gives 32768, a 17 bits signed value that can't fit in the 16 bits signed values sine table. This means that this table may not contain values matching exactly -1 and 1, but approaching values: -32767 and 32767.
This loss of accuracy is not acceptable. For this reason, N must be reduced from 15 to 14. Therefore, the SWAP has to be followed with a 2 bits ROL.L instead of a 1 bit one. Let's show how this fits in the limits:
move.w #$7FFF,d0 ;2^15-1=32767 move.w #$C000,d1 ;sin(-90)*2^14 muls d1,d0 ;$E0004000 swap d0 ;$4000E000 rol.l #2,d0 ;$00038001 => $8001=-32767 OK move.w #$7FFF,d0 ;2^15-1=32767 move.w #$4000,d1 ;sin(90)*2^14 muls d1,d0 ;$1FFFC000 swap d0 ;$C0001FFF rol.l #2,d0 ;$00007FFF => $7FFF=32767 OK
The final version of the sine table looks like that:
sinus: DC.W 0 ;sin(0)*2^14 DC.W 286 ;sin(1)*2^14 DC.W 572 ;sin(2)*2^14 DC.W 857 ;sin(3)*2^14 ;...
The 16 bits result of the multiplication of the sine of the angle stored in D0 by a 16 bits signed value stored in D1 is computed like this:
lea sinus,a0 lsl.w #1,d0 move.w (a0,d0.w),d2 muls d2,d1 swap d1 rol.l #2,d1
Let's define SCROLL_DY as the height of the strip the sine scroll fits into in the screen. SCROLL_AMPLITUDE must be so that (SCROLL_AMPLITUDE>>1)*(1+sin(βx)) gives values lying in [0, SCROLL_DY-16]. This is possible only if this interval contains an odd number of values, which means that SCROLL_DY-16 is even. That turns out well, because we want the scroll to be vertically centered in the screen at the ordinate SCROLL_Y, which implies that SCROLL_DY must be even because DISPLAY_DY, the height of the screen, is even itself. That means:
SCROLL_DY=100 SCROLL_AMPLITUDE=SCROLL_DY-16 SCROLL_Y=(DISPLAY_DY-SCROLL_DY)>>1
As long as we are there, let's define the constants for the abscisse where the scroll starts, and the number of pixels of its width. By default, the width is the width of the screen:
SCROLL_DX=DISPLAY_DX SCROLL_X=(DISPLAY_DX-SCROLL_DX)>>1
The ordinate of each column of a character of the sine scroll can now be computed, which implies that we may now draw this character. But first, we have to scroll and animate the sine scroll...